Database Seeders Using Lucid ORM

In my last post, I demonstrated how we can use LucidORM to track and manage database changes. Today, I will discuss using seeders to populate our database.
The Problem
We will talk about two problems I have with populating the database for this rewrite.
Problem 1A
While I have a database with about 15 years’ worth of data, for this project, I am rebuilding it from the ground up. Before this rewrite is done, I will have torn down and rebuilt the new database numerous times, which means that I need a consistent method of pulling data from the old database and inserting it into the new schema.
Problem 1B
I am changing the data type used for my primary key. In many tables, I use a UUID generated from the ColdFusion code as the primary key (it is stored as varchar(36)). I want to change this because every time I insert a row into any of these tables, the index needs to be rewritten entirely because the values are not sequential. It may mean little in my small data set, but part of my reason for this rewrite is to make it easier for others to manage their golf leagues. When that happens, rewriting the indexes can cause performance issues. To accomplish the porting of PKs, I need to map the old primary key to the new primary key so that when I add foreign key relationships, I use the correct value and pointer to the PK in the related table.
The Solution
I decided to use seeders as the solution to both of these problems.
Problem 1A
Using seeders, I will build a process to run INSERT scripts against the new schema. These scripts will extract data from the old database and insert it into the new schema.
Problem 1B
The way I decided to solve the problem of changing the primary keys from varcahr(36) to int was to set up a table named pkmap in the new schema. This table consists of three columns:
old_pk: The primary key from the old database.new_pk: The primary key for the new database.object: The name of the table the PKs refer to.- I added this to delete data from this table if I perform a rollback on a related table.
Here is the migration I created to set up this table:
import { BaseSchema } from '@adonisjs/lucid/schema'
export default class extends BaseSchema {
protected tableName = 'pkmap'
public async up () {
this.schema.createTable(this.tableName, (table) => {
table.string('old_pk', 36).notNullable()
table.bigInteger('new_pk').notNullable()
table.string('object', 50).notNullable()
})
}
public async down () {
this.schema.dropTable(this.tableName)
}
}
I also updated the migrations for the league and season tables to remove related rows in the pkmap table when we roll back any changes.
I added this line of code to the down() method of the league migration.
await this.db.rawQuery("delete from pkmap where object = 'league'")
I added this line to the down() method on the season migration.
await this.db.rawQuery("delete from pkmap where object = 'season'")
Creating a Seeder
Just like creating a migration, there is a command we can run to generate a seeder. To create a new seeder for the league table, I ran this command:
node ace make:seeder league
We will see a message similar to the text below when creating the file.
DONE: create database/seeders/league_seeder.ts
I will not lie; I fully expected the file name to include ‘leagues’ rather than ‘league’. This inconsistency in behavior (even though it is what I would prefer) caused some knicker twisting, but not much.
The content of this file will resemble:
import { BaseSeeder } from '@adonisjs/lucid/seeders'
export default class extends BaseSeeder {
async run() {
// Write your database queries inside the run method
}
}
To populate the database, we add whatever code we want to execute in the run() method. There are several methods for adding data. Because of my unique situation, I will use a raw query to extract data from the old database.
Here is the code I used for the league seeder.
import { BaseSeeder } from '@adonisjs/lucid/seeders'
import db from "@adonisjs/lucid/services/db";
export default class extends BaseSeeder {
async run() {
await db.rawQuery(`insert into pkmap select id, rank() over( order by id), 'league' from golf_league_manager.league`)
await db.rawQuery(`insert into league(id, name, enabled)
select
pk.new_pk,
l.name,
l.enabled
from golf_league_manager.league l
join pkmap pk on l.id = pk.old_pk`)
}
}
First, you’ll notice I added an imprt to get the db object.
In the body of the run() method, you’ll see that I am running two different queries.
The first query inserts the old_pk value from the old table, another value that represents the row number for the league when selecting all rows, and then the string ‘league’.
The second query inserts data into the new league table using INSERT INTO...(SELECT) syntax. This query’s SELECT portion joins the league table in the old schema to the pkmap table in the new schema.
Here is the seeder for the season table.
import { BaseSeeder } from '@adonisjs/lucid/seeders'
import db from "@adonisjs/lucid/services/db";
export default class extends BaseSeeder {
async run() {
await db.rawQuery(`insert into pkmap select id, rank() over( order by id), 'season' from golf_league_manager.season`)
await db.rawQuery(`insert into season(
league_id,
name,
start_date,
rules,
rules_published,
settings,scoring_id,
registration_open,
registration_token
)
select
(select fk.new_pk from pkmap fk where fk.old_pk = s.leagueId),
s.name,
s.startDate,
s.rules,
s.publishRules,
s.settings,
s.scoringId,
s.registrationOpen,
''
from golf_league_manager.season s
join pkmap pk on s.id = pk.old_pk
order by s.startDate;`)
await db.rawQuery(`update league l set l.current_season_id =
(select s.id from season s where league_id = l.id order by start_date desc limit 1)`)
}
}
There are three queries in this seeder. The first two are similar to the league seeder queries. They insert rows into the pkmap table and populate the season table.
The third query updates the league table by setting the value of the current_season_id column with the id of the season that has the latest start_date.
Running Seeders
To run our seeders, we use a command with the following syntax:
node ace db:seed
This command will run all the seeders in the seeders folder. ** Unlike migrations, seeders are not tracked. ** Exercise caution when running seeders to ensure you do not run them more than once per table, or you will end up with duplicate data. With my examples, it will throw an error.
Keep in mind that the files in the seeder folder are run in the same order in which they appear in the folder.
Running Interactively
We can run seeders interactively by using this command:
node ace db:seed -i
When we run this command, we will see a list of available seeders, and we can specify which one to run.
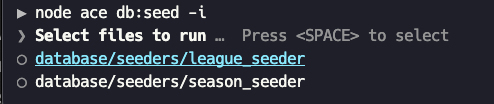
To specify a custom order for the seeders to be run, check out the documentation from Lucid ORM.
The Result
Once I ran my seeders, my new tables were populated with data from the old database.
Here is the data from the league table.
+----+---------------------------------------------+---------+---------------------+---------------------+-------------------+
| id | name | enabled | created_at | updated_at | current_season_id |
+----+---------------------------------------------+---------+---------------------+---------------------+-------------------+
| 1 | Locust Hill Summer Golf League | 1 | 2024-07-12 12:27:12 | 2024-07-12 12:27:12 | 27 |
| 2 | Frederick County Public Schools Golf League | 1 | 2024-07-12 12:27:12 | 2024-07-12 12:27:12 | 26 |
+----+---------------------------------------------+---------+---------------------+---------------------+-------------------+
Wrap Up
Using seeders in Lucid ORM as part of my development process, I can easily and consistently populate data into the new database. I need to be careful only to run the seeders once unless I have rolled back my migrations, or else I could get duplicate data or errors when running the seeders. Unless I encounter an interesting situation, I will not talk about any other migrations or seeders in this series. In my next few posts, I will talk about using models in AdonisJS and setting up some basic routing.
